The New Edisons — How Tech Giants Are Rewiring the Grid


Executive Summary
As AI's immense energy demand collides with the aging public grid, tech giants like Amazon and Google are becoming the "New Edisons" of our time by constructing their own parallel, privately-controlled power systems. No longer treating energy as a commodity, they now engineer it as a strategic asset for competitive advantage—securing private nuclear generation to bypass grid queues and lock in prices, transforming data centers into flexible resources, and profiting from the very market instability they help create. This convergence is fundamentally rewiring the economics and control of global energy, sparking a contest to determine who will write the rules for our future.
On a March afternoon in 2024, Amazon Web Services purchased a 1,200-acre data center campus beside Pennsylvania's Susquehanna nuclear plant for $650 million. The deal included rights to 960 MW of power—nearly 40% of the reactor's output. What looked like a real estate transaction was actually something more fundamental: a tech company buying not just electricity, but control over how that electricity moves through the grid.
By November, federal regulators had rejected the original behind-the-meter arrangement. Amazon didn't retreat. Instead, the company and reactor operator Talen Energy restructured the deal as a $18 billion, 20-year power purchase agreement covering 1.92 GW through 2042. The paperwork changed; the physics didn't. Amazon had secured two decades of carbon-free baseload power while competitors waited years in interconnection queues.
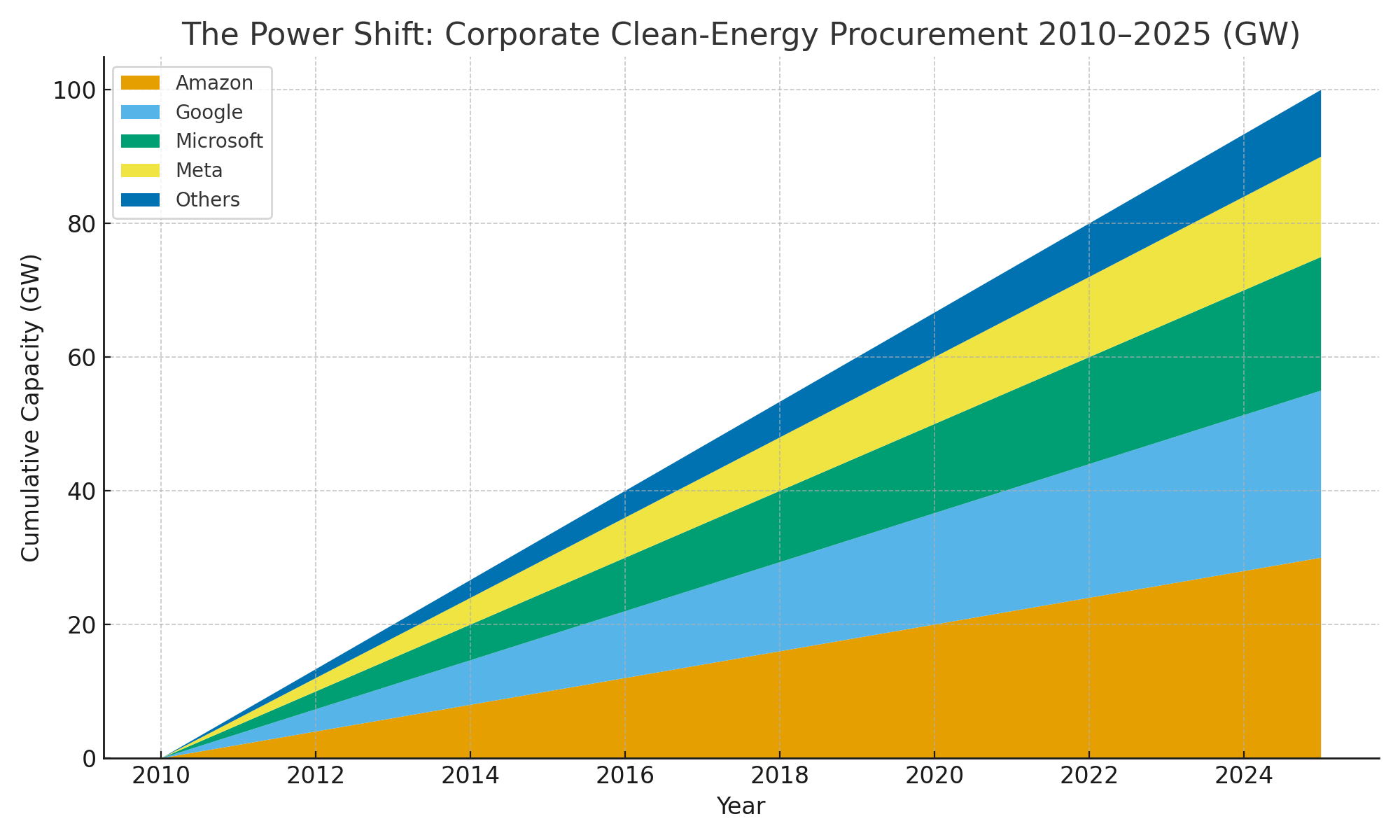
This isn't just about keeping servers running. The convergence of AI computing and energy infrastructure is creating a parallel power system with its own rules, economics, and strategic logic. The companies building this system have learned that energy isn't a commodity to purchase—it's an asset to engineer.
The Programmable Load
A 100-megawatt AI data center draws enough power to light 75,000 homes. But unlike residential demand, this load is fundamentally different: it can be instructed, paused, and rescheduled with millisecond precision.
Training a frontier AI model like GPT-4 required 25,000 NVIDIA A100 GPUs running for 90-100 days, consuming between 51,773 and 62,319 MWh. Published estimates suggest the training run consumed between 35-60 GWh total (depending on cluster configuration and utilization patterns), implying an average facility load of 22-30 MW when accounting for PUE of 1.5. The result is a block of demand so steady that grid operators treat it like generation—except it can be interrupted.
The mechanism is called checkpointing: saving the complete state of a training run to persistent storage. For large language models, checkpoint intervals typically run 30 minutes to several hours. This means an AI training cluster can tolerate interruptions of 8-12 hours without losing significant computational progress. In a 512-GPU cluster, an 8-hour interruption costs over $8,000 in lost compute time—but that's manageable if the revenue from grid services exceeds the opportunity cost.
The economics shift when we examine what's being trained. Batch learning—the standard approach for foundation models—processes data in discrete chunks. A demand response event becomes a planned pause between batches. Online learning systems that update continuously from real-time data streams can't tolerate these gaps, but they're not what's driving the massive power draw. As one industry analysis notes, by 2030 roughly 70% of data center demand will come from AI inference applications—the real-time services that answer user queries.
Inference workloads are different. When a user asks ChatGPT a question, the acceptable latency runs from 345 milliseconds to 2.27 seconds for the first response token, then 15-60 milliseconds per subsequent token. A 15-minute demand response event is several orders of magnitude longer than these sub-second requirements. You can't turn off inference for grid services.



